2022年3月24日,距离北京科技大学70周年校庆还有一个月的时间。437必赢会员中心网页版工商管理系“人力资源大数据实践项目”第三次授课如期开始。按照疫情防控期间相关要求,本次授课依旧采取腾讯会议的方式进行。本课程有幸邀请到新道科技股份有限公司高级讲师曹晔进行讲解。第三次授课,曹老师基于知识遗忘曲线的考虑,首先帮助同学们进行了前两节课程内容的回顾与总结,强调了重点和难点。之后开始今天的新的内容——数据挖掘算法的讲解教学。
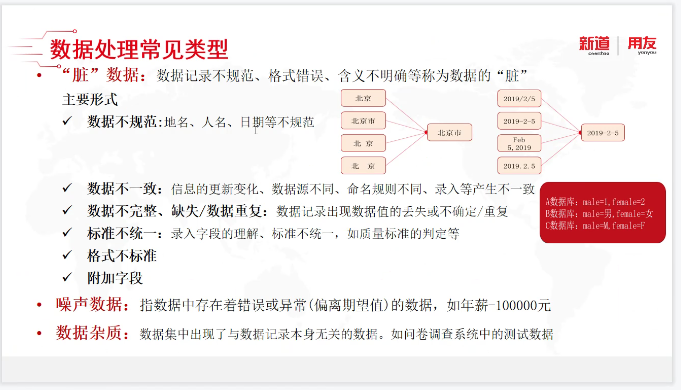
曹老师通过介绍数据挖掘的应用场景来引出数据挖掘算法的内容,今天课程主要围绕数据挖掘算法中的回归分析和分类分析展开讲解。曹老师首先讲解了数据处理的常见类型,详细介绍了“脏”数据的主要形式。“脏”数据的主要形式有:数据不规范、数据不一致、数据不完整、缺失/数据重复、标准不统一、格式不标准和附加字段。最常见的“脏”数据有数据不规范和数据不一致,其中标准不统一的“脏”数据是我们人工查验难以发觉的,但是使用大数据对其进行数据预处理就会显得轻松许多。
接着曹老师开始教授同学数据预处理的方法。对爬取数据的预处理主要有四种方法,分别是数据清理、数据集成、数据变化和数据归约。数据清理即填写空缺的数值,平滑噪声数据,识别、删除孤立点,检查不一致性。数据集成是指把多个数据源的数据整合并储存到一致的数据库中。数据变换,顾名思义,将数据进行转换或归并,构成适合处理的规范化数据处理格式。数据归约是从原有的巨大数据库集中获得一个简约的数据集,并使这个简约数据集保持原有数据集的完整性。
随后曹老师讲解了本节课的重难点——回归分析和决策树。回归分析是根据事物变化情况,找到影响结果变化的主要、次要因素,考察各自变量对因变量的影响强度,并通过模型对结果进行预测分析的方法。回归分析第一个作用是研究一个连续变量的取值随着其他变量的数值变化二变化的趋势。其通过回归方程解释两变量之间的关系显得更为精确,可以计算出自变量改变一个单位时因变量平均改变的单位。除了描述两变量的关系以外,通过回归方程还可以进行预测和控制,这在实际工作中尤为重要。
关于决策树的知识,曹老师指出决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
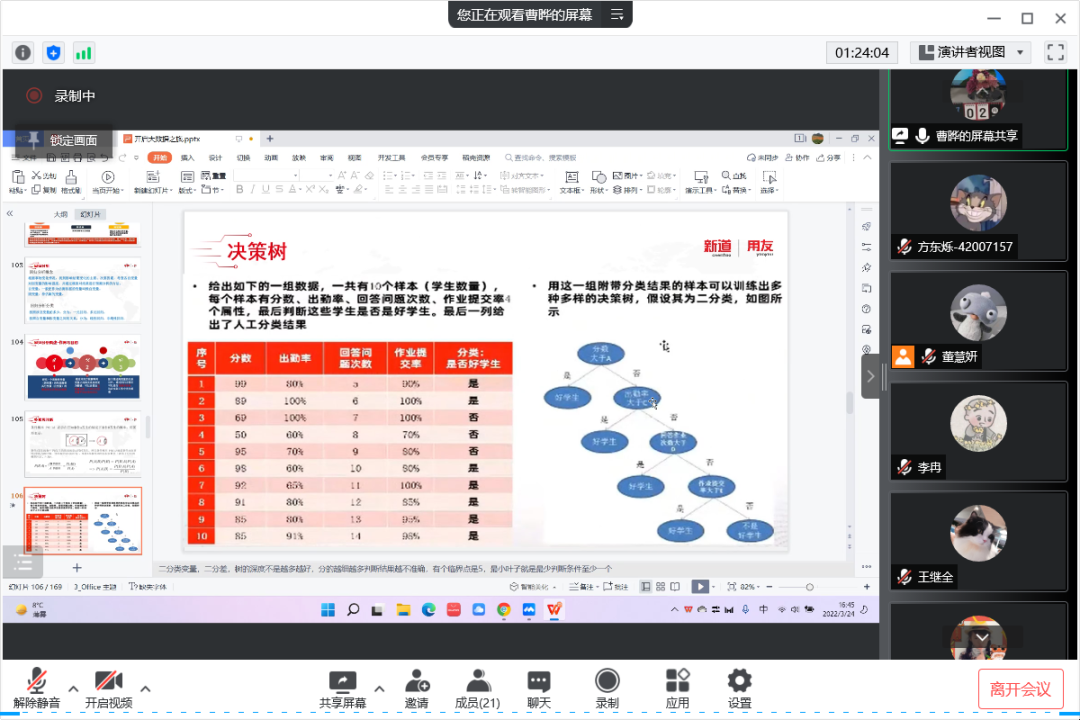
最后,曹老师对今天所讲内容进行了归纳总结,再次强调了回归分析和决策树的重难点,希望同学们在课后可以好好地“消化”知识,熟练掌握。同学对本节课的反应比较积极,纷纷表示自己在课后会努力巩固课堂知识,熟练掌握建模工具。
供稿|工商管理系
责编|赵西爱
审核|范小华